- OWASP Top 10 LLM Apps Newsletter
- Posts
- OWASP LLM Top 10 Newsletter - June '24 Edition
OWASP LLM Top 10 Newsletter - June '24 Edition
Who will make the V2 cut ? Not that easy !!
Krishna Sankar
June 18, 2024

The race is on - the candidates are in & the fun starts NOW !
We are talking about the OWASP Top 10 LLM V2 deliberations !!
We have 34 candidates & all of us need to vote ! (See below for details)
An excellent opportunity to influence & participate in the future of LLMs … Even dare to project the future of LLMs - which, of course, is a perilous occupation, as even the wildest predictions will be proven wrong by our (not so) new computer overlords i.e., Transformers and friends …
Please read on - This newsletter is entirely dedicated to the v2 candidates (34 of them, obviously some can be combined); we will visit all the v2 proposals …
The voting starts on June 16, 2024 (I didn’t realize, it is today!!) - Vote Early & Vote Often 😇 …

Back to the earth, pragmatically we have a ton of questions to answer :
Should “Top 10 LLM” remain Top 10 LLM or would it be better off becoming “Top 20 LLM” or even “Top 40 LLM” (as we have 34 new candidates !!) ?
What changes are needed for the current entries ? Are they still relevant ?
More importantly, How can we make the Top 10 LLM more approachable, accessible and consumable by a wider audience - especially those with a high information overload and a (very !) low attention span?
As our esteemed contemporary Sandy Dunn puts it “… new consumption model where the content is immediately interesting and people can understand what you are writing about quickly because let's face it - we're all speed reading - there is just way too much content”!
Top 10 LLM V2 Candidates
Reading and understanding the candidates, by itself, gives us a good insight into the security, safety and trust of LLMs. It’s time well spent.
Here’s the list … (Of course, you can read the gory details at our voting form)
All the Candidates are here
Agents
Vulnerable Autonomous Agents : ALAs (Autonomous LLM-based Agents) are an area expected to mature significantly. The threats include Malicious Agent Environment Influence, Hacking of Agent's Internal State, Interference with ALA Adaptability and Vulnerable Agent Logic. Insightful details here.
Agent Autonomy Escalation : When a deployed LLM-based agent (such as a virtual assistant or automated workflow manager) gains unintended levels of control or decision-making capabilities, it can lead to harmful actions. This can result from misconfigurations or exploitation by malicious actors.
Alignment, Safety & Trust
Dangerous Hallucinations : Instances where the model generates plausible but false information that is confidently presented as accurate.
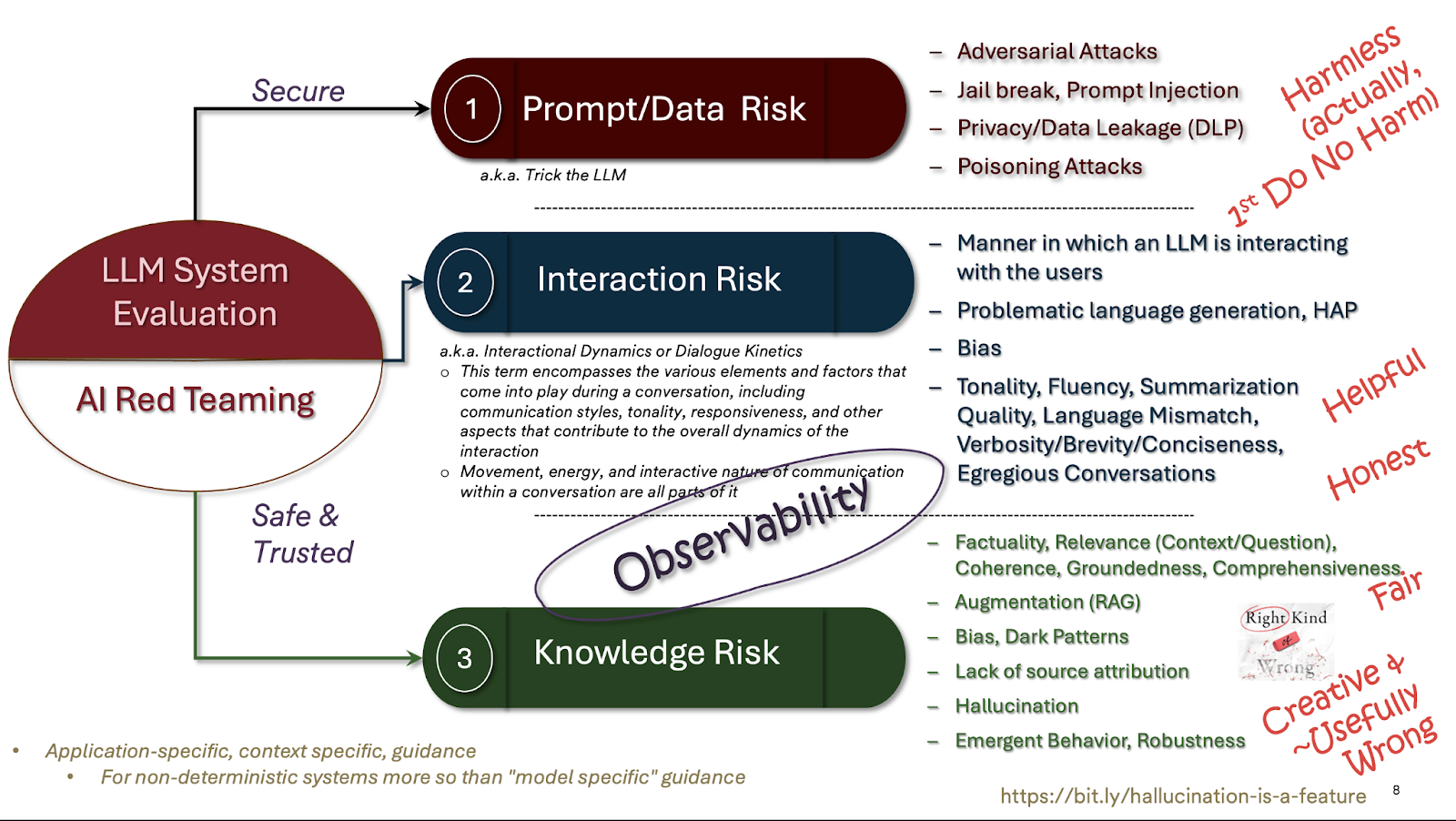
Alignment & Value Mismatch : LLM responses that violate organizational policies and values, triggering Response Interaction Risk from HAP (Hate/Abuse/Profanity) to contextual toxicity, Bias, misinformation, egregious conversation and prompt brittleness. A quick diagram below:
RAG & Fine tuning : Risks include breaking safety and alignment, outdated information, data poisoning, data freshness and synchronization and access control issues.
Rewrite LLM09 : Overreliance : Currently it reads “Overreliance on LLMs can lead to misinformation or inappropriate content due to "hallucinations."“.
But, Over reliance doesn't cause hallucination or vice versa.
Hallucination/emergent behavior should have it's own place in Top n, not in this.
Also need to add a very important risk - the transition to AI mediated Enterprise Knowledge Access leading to lack of agency, data non-uniformity and system opacity.
Cyber Threats
Adversarial Use of AI for Red Teaming and Cyber Operations : Leveraging AI technologies to conduct sophisticated offensive operations including creating deepfakes, spreading misinformation, and conducting cyber warfare.
AI-Assisted Social Engineering : Malicious actors can automate and scale social engineering efforts, making attacks more persuasive, targeted, and challenging to detect.
Multimodal Manipulation: Using AI to generate fake news articles with fabricated images, manipulated audio, and persuasive text to create a highly believable and misleading narrative.
Deepfake Threats: AI-generated synthetic media can impersonate individuals or manipulate information, posing risks to identity and authentication systems as well as access control mechanisms
Voice Model Misuse: Unauthorized use of LLM-generated voices to deceive, manipulate, or harm individuals or organizations, including financial fraud, identity theft, reputational damage, and erosion of trust in AI-generated content.
Multi modality
Multimodal Injections: Attacks that embed instructions in various media forms—video, audio, images—that the model takes as input. More juicy details here
Advanced LLM Capabilities
Function Calling Attack : Risks associated with LLMs that allow users to execute custom functions, potentially exposing sensitive information.
Unwanted AI Actions by General Purpose LLMs : When AI systems using general-purpose LLMs are not tailored to specific contexts, leading to illegal or undesirable actions.
User Interface Access Control Manipulation: Exploiting LLMs (that dynamically create or modify user interface (UI) elements based on user input or prompts) to manipulate UI elements, potentially generating unintended data.
Adversarial Attacks
Bypassing System Instructions Using System Prompt Leakage : System prompts meant to control the model's behavior can be inadvertently revealed, allowing manipulation.
System Prompt Leakage : Unintended disclosure or extraction of the system prompt, could contain sensitive information, instructions, or data used to guide the LLM's behavior and allow attackers to craft prompts that manipulate the LLM's responses
Adversarial Inputs : Crafting subtle, malicious perturbations in the input data that deceive Large Language Models (LLMs) into making incorrect or harmful predictions. This type of attack leverages the model's sensitivity to small changes in input, potentially causing significant and unexpected outcomes.
Insecure Input Handling: If prompts are not securely handled, they can be intercepted or stolen, compromising confidentiality.
Indirect Context Injection: Manipulating interactions with an LLM to generate harmful or unintended outputs.
Model Inversion : Attacks that reconstruct sensitive training data by querying the LLM and analyzing its responses.
Embedding Inversion : Extracting sensitive data from input embeddings.
Backdoor Attacks : Embedding hidden triggers in the model during training, causing harmful actions under specific inputs
Sensitive Information Disclosure : LLM applications can reveal sensitive information through their output.
Privacy Violation : As Large Language Models (LLMs) gain more power and widespread use in various applications, the risk of these models being used in ways that infringe upon user privacy escalates. Details here
Unauthorized Access and Entitlement Violations : When LLM systems fail to enforce proper access controls.
Developing_Insecure_Source_Code : Details here
Rewrite LLM01: Prompt Injection : Lot more interesting additions. Details here
Application Design
Insecure Design : Insecure Design is the result of the insufficient knowledge about AI products, while developing or utilizing applications such as hiring process, trending data, Government policies, Reviews based of public data, etc
Improper Error Handling: Leading to security vulnerabilities, including information leakage, denial of service and remote code execution.
LLMOps/Infrastructure
Unrestricted Resource Consumption : Occurs when a Large Language Model (LLM) application allows users to consume excessive resources without proper limitations or controls
Resource Exhaustion : Encompasses both Denial of Service (DoS) and Denial of Wallet (DoW) attacks. These attacks exploit the intensive resource utilization of LLMs, causing service disruption, degraded performance, and financial strain.
Malicious LLM Tuner : A Malicious LLM Tuner is an individual with the technical expertise to manipulate Large Language Models (LLMs) for malicious purposes. These individuals exploit the inherent flexibility of LLMs by adjusting configuration settings to achieve unintended consequences
Rewrite LLM05 Supply Chain Vulnerabilities : Details here
Wow, that's a lot to take in !
Call to action : Your mission, should you choose to accept it, is to evaluate these candidates and vote [here] Steve has done a good job explaining the process …
What do you think ?
Should we accept the candidates (i.e., add them to the Top 10 LLM, combine them with existing ones) or ignore them ? Create/Update/Ignore ?
One more thing - another call to action …
Please consider contributing data to the Data collection initiative. This blog has all the gory details !

From 𝐌𝐚𝐲 𝟐𝟎𝐭𝐡 𝐭𝐨 𝐉𝐮𝐧𝐞 𝟑𝟎𝐭𝐡, 2024, we are inviting security professionals, organizations, and researchers to contribute data that will help shape the future of secure LLM AI applications. Your participation will ensure that our findings are comprehensive, accurate, and reflective of the latest trends in AI security.
Cheers & See y’all next time …
Once more … please click on this voting link as a reminder to revisit and vote later (this might not help - as of now I have 498 tabs open 🤔) Dead line is June 30th